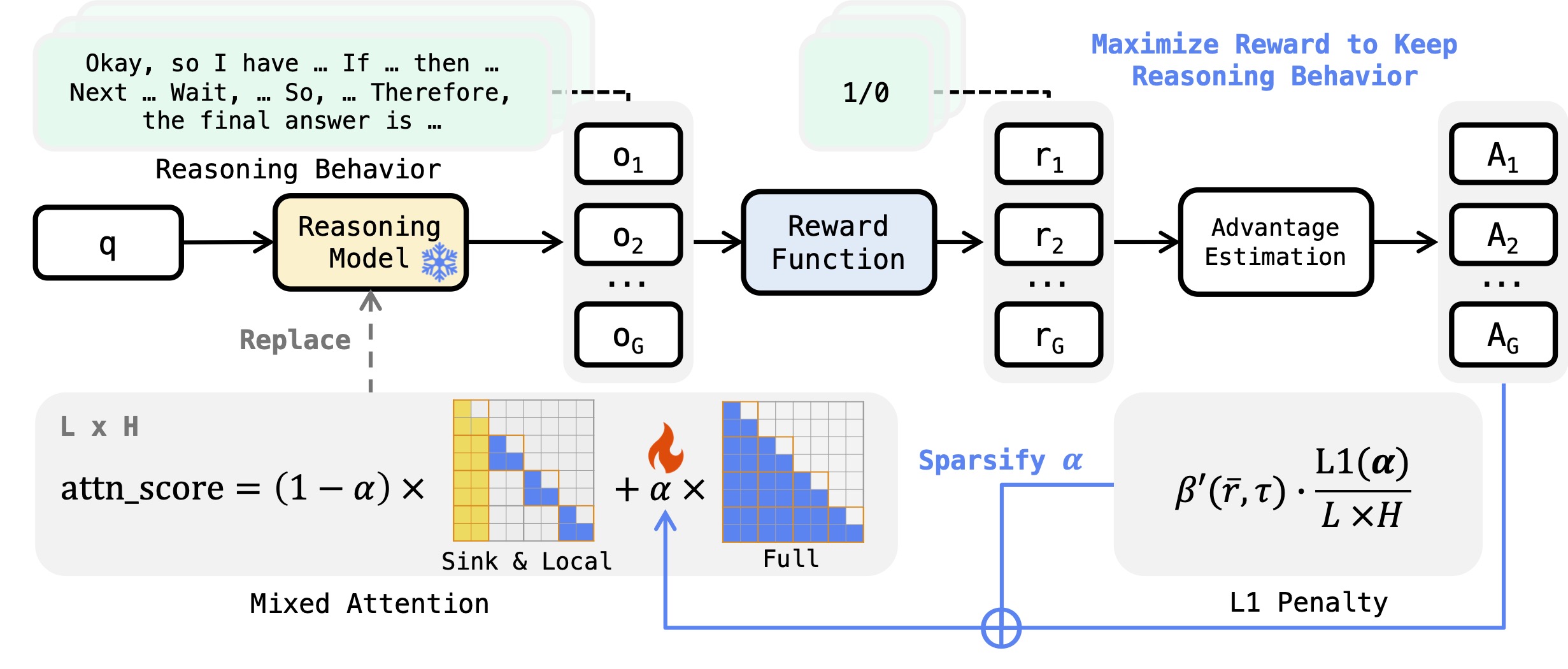
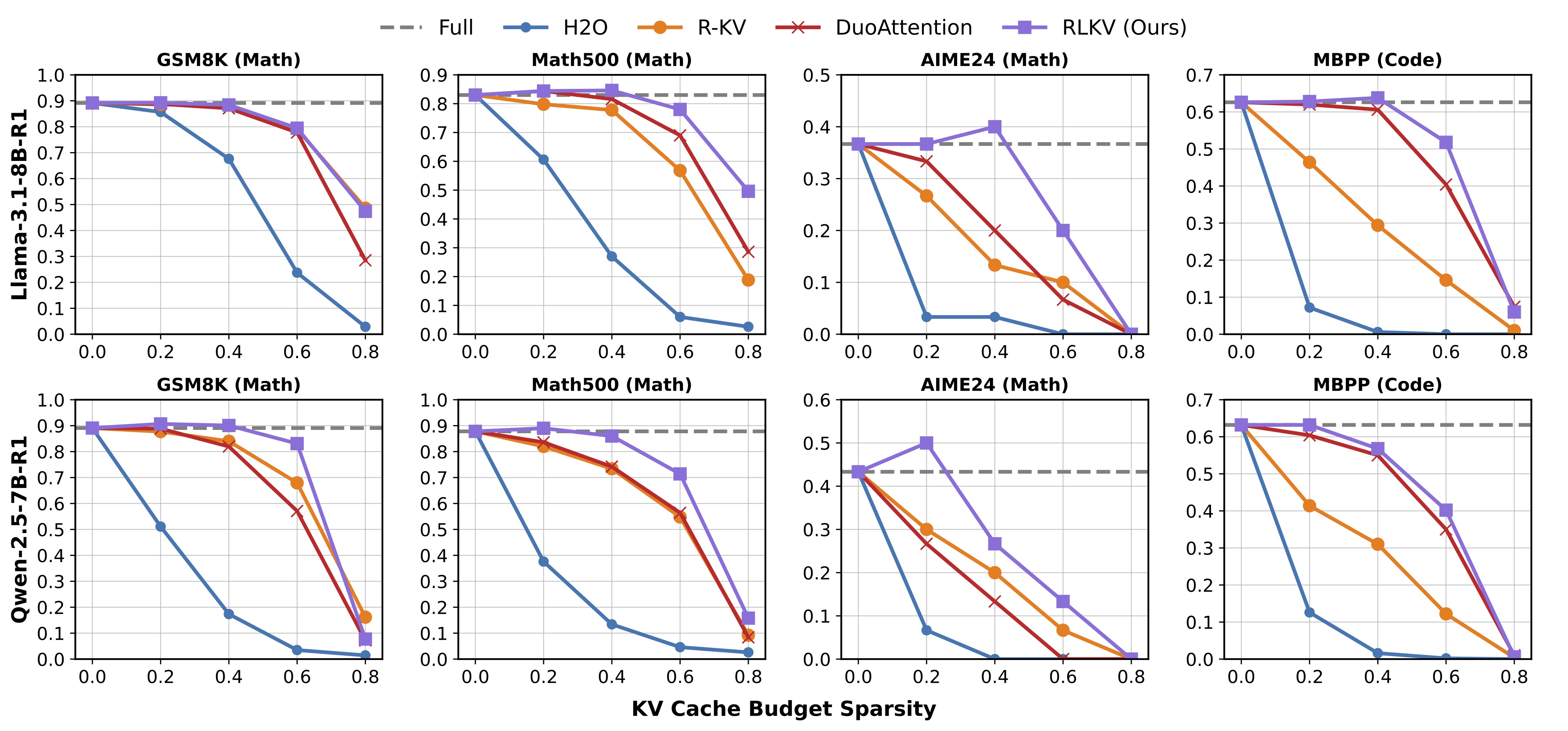
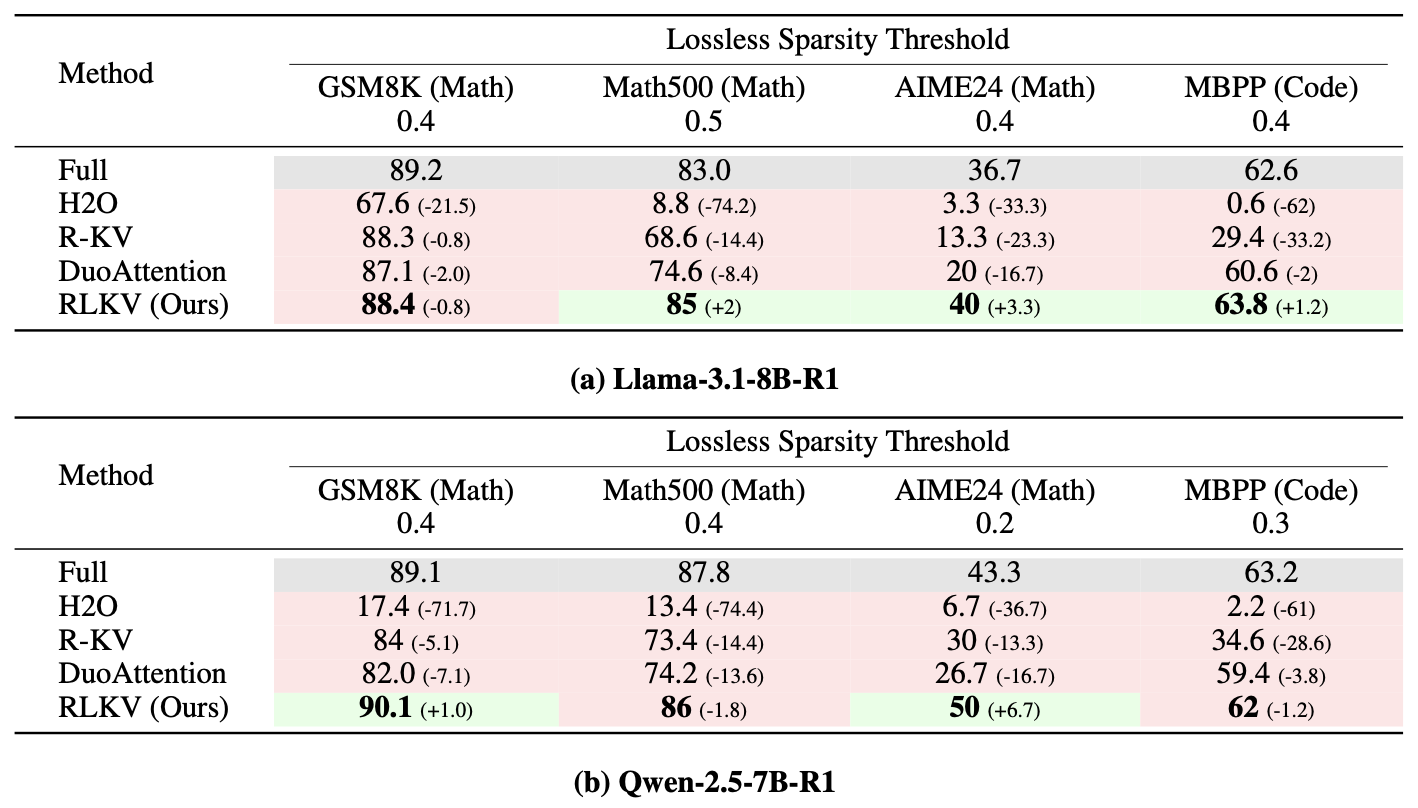
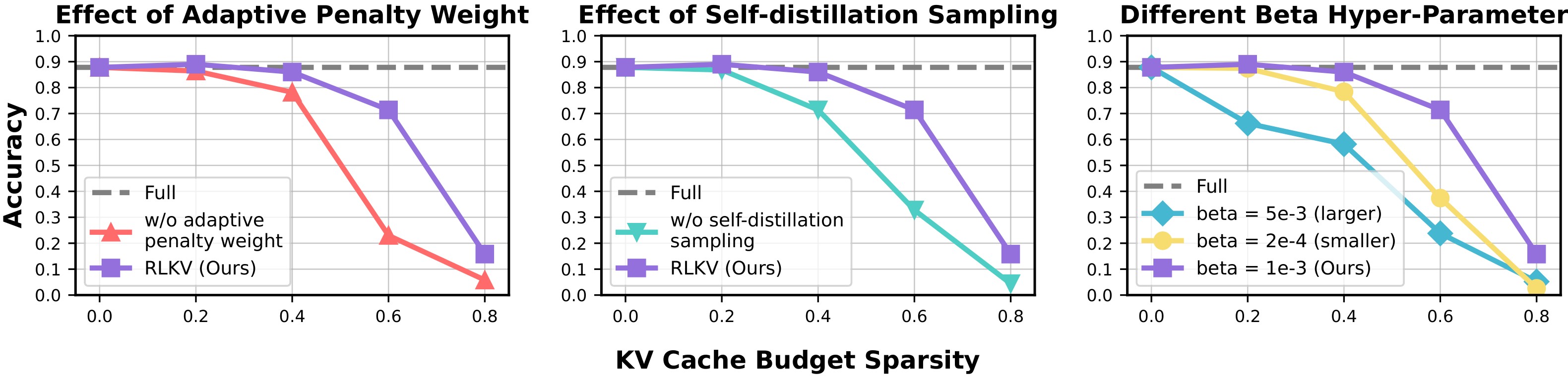
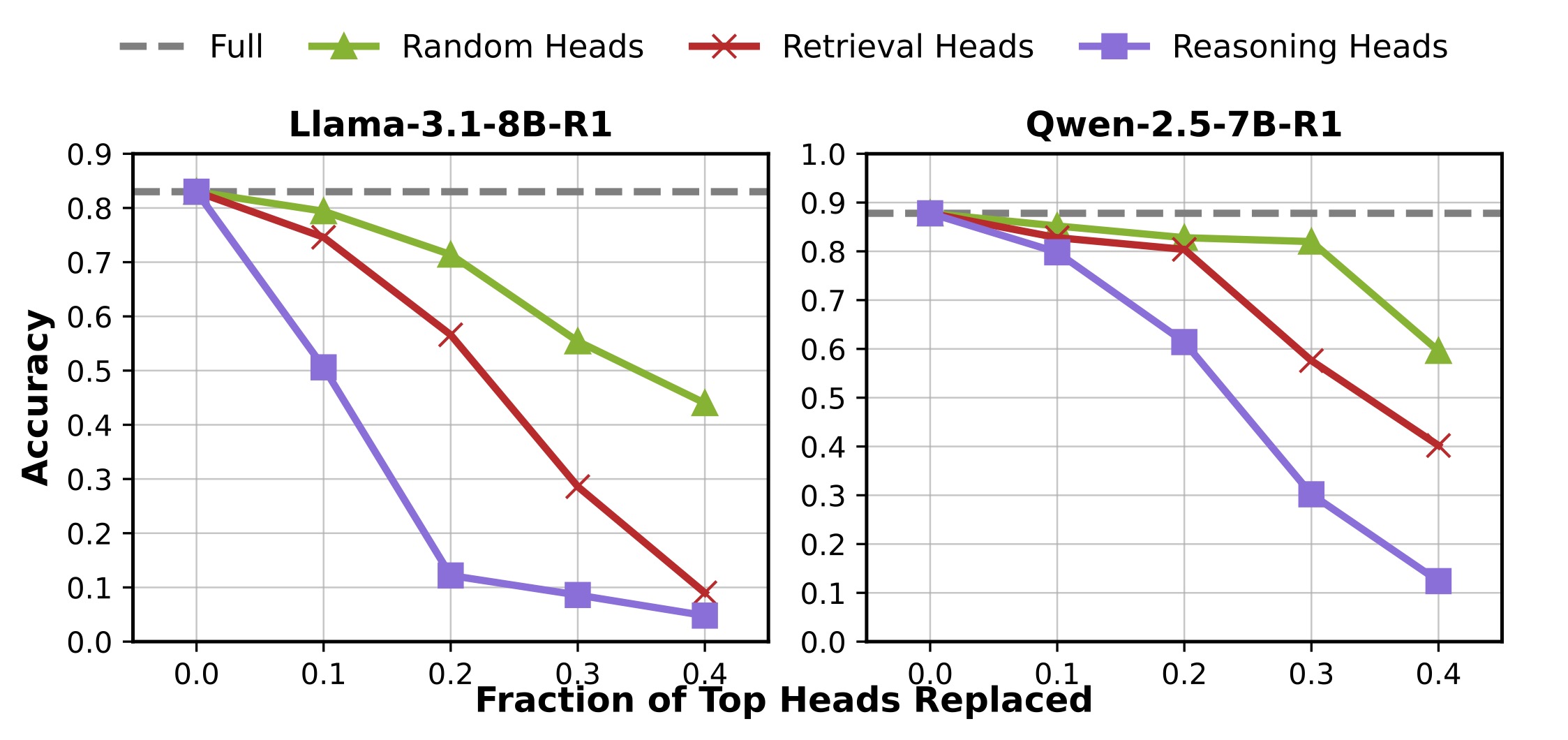
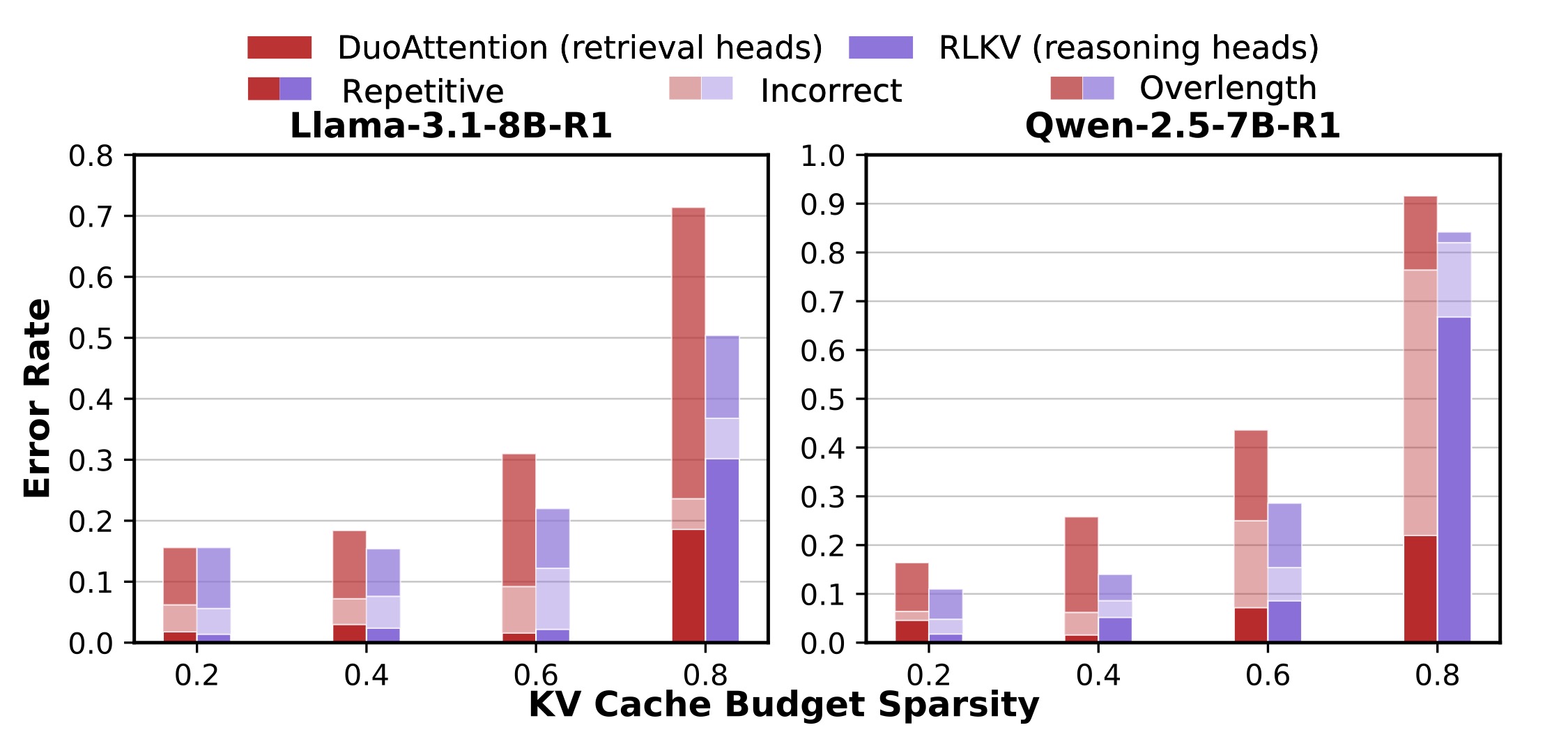
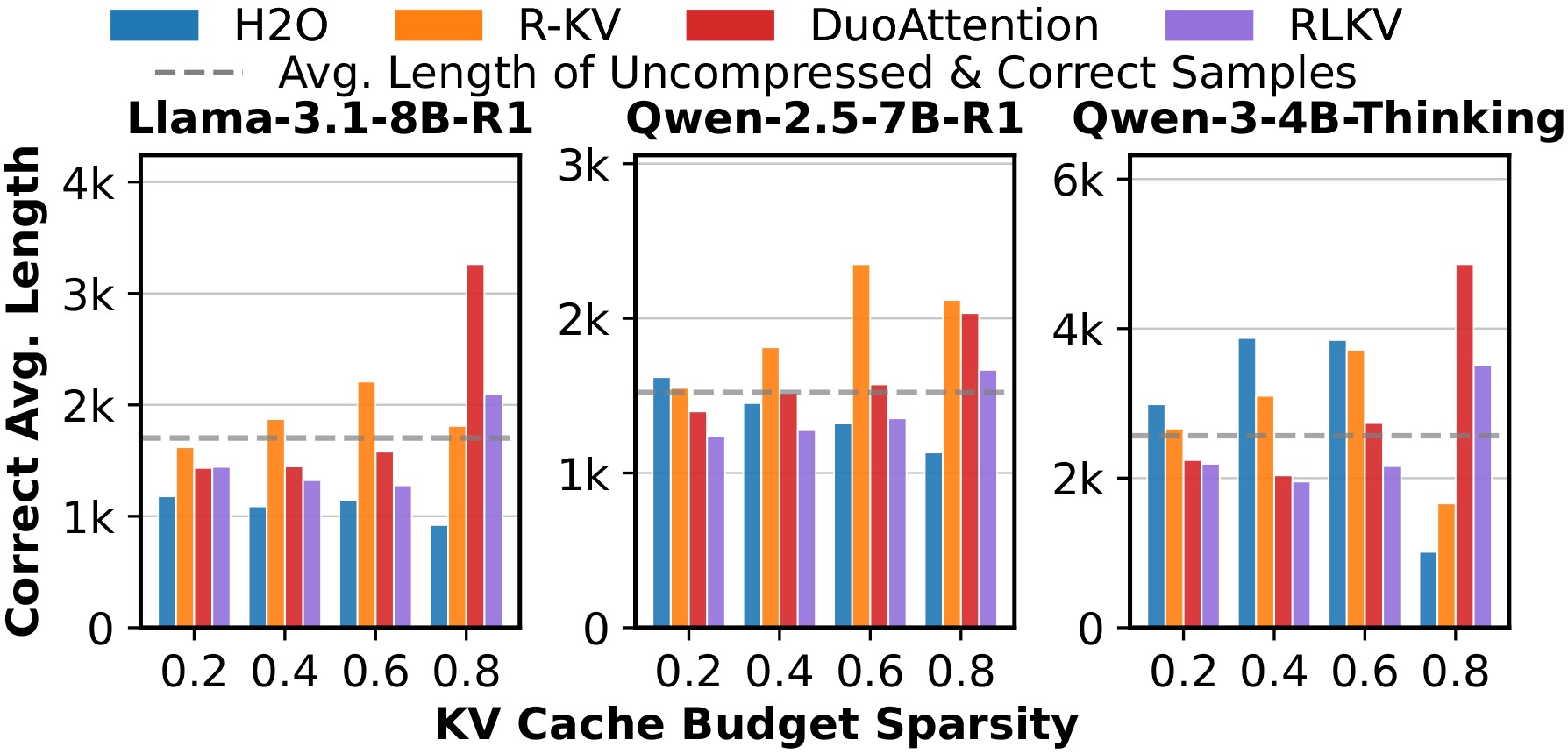
- 2026/05: RLKV is accepted to ICML 2026! See you in Seoul!
- 2026/04: RLKV is supported in SGLang inference (see code).
- 2026/03: RLKV is presented at the LIT @ ICLR 2026 workshop (Latent & Implicit Thinking — Going Beyond CoT Reasoning).
- 2025/10: arXiv preprint is released.